1Learning Outcomes¶
Illustrate a shared memory multiprocessor architecture with caches.
Define cache coherence misses.
🎥 Lecture Video
🎥 Lecture Video
🎥 Lecture Video
2Shared memory multiprocessor (SMP)¶
Recall that in our multicore processor architecture we assume a shared memory model to enable multithreaded processing. This model is called a shared memory multiprocessor (SMP), which assume a single physical address space across all processors.[1]
Given our understanding of the memory hierarchy and Jim Gray’s space-time analogy of locality, memory is a performance bottleneck even with one processor. Shared memory multiprocessors use caches to reduce bandwidths on main memory, as shown in Figure 1.
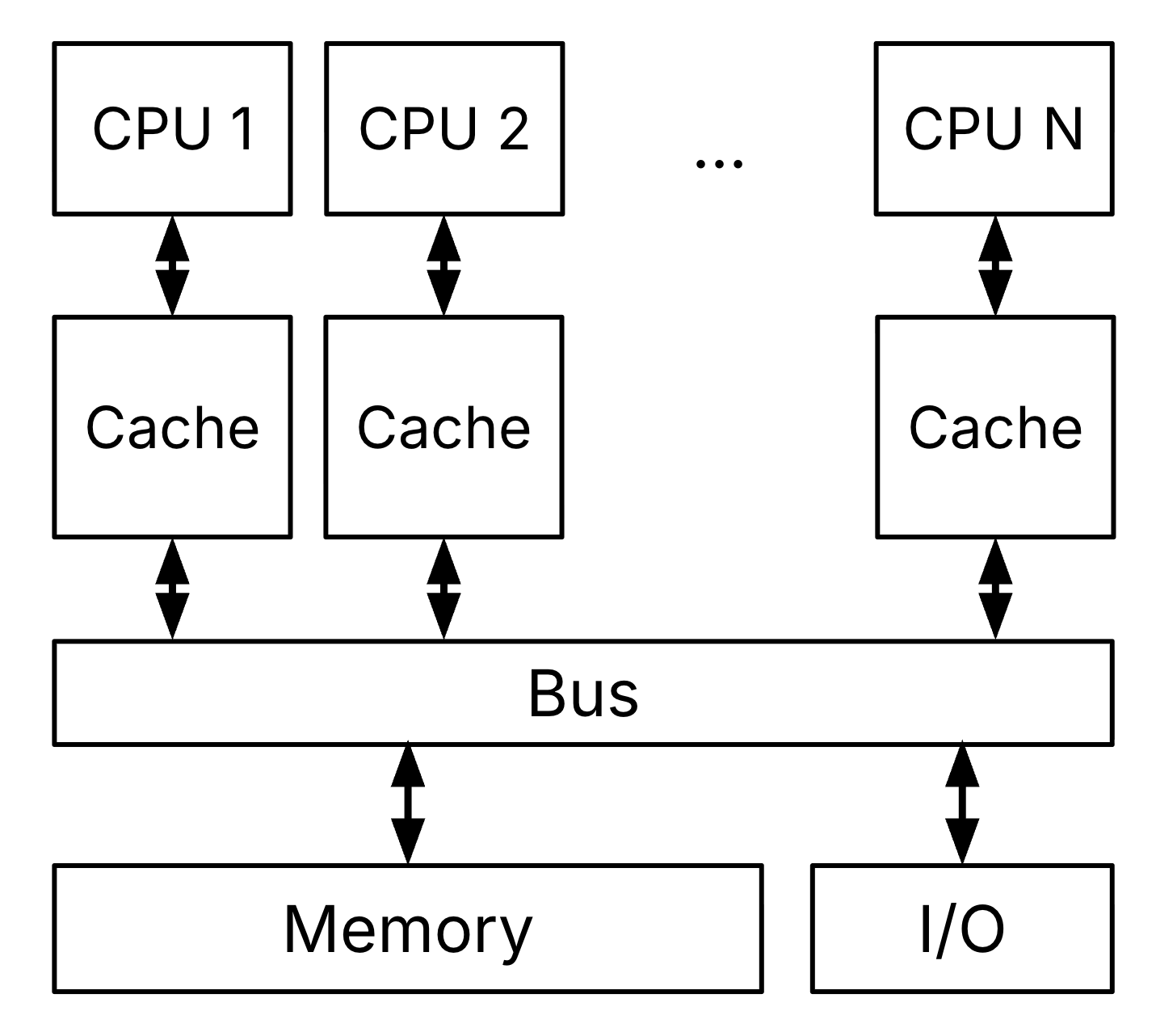
Figure 1:Shared-memory Multiprocessor (SMP) with multiple cores and a single, coherent memory.
Solution to Exercise 1 #
True For all other instructions, we don’t need to read the data that is read out from DMEM, and thus don’t need to wait for the output of the MEM stage.
Notes about Figure 1:
Each CPU has its own cache(s), e.g., an L1 cache.
All CPUs communicate with each other and memory through a communication bus.
One bank of memory (DRAM) is shared by all CPUs.
3Cache Coherence Problem¶
In a different section, we discuss how threads running on multiple processors can use locks to synchronize access to shared data across processors. In this section, we discuss an additional problem that arises when we introduce caching: cache coherence.
Consider three example memory accesses on a dual-core system. Assume the word 20 is initially in memory @ address 0x5000 , and we perform three memory accesses:
CPU 1 reads word @ address
0x5000.CPU 2 reads word @ address
0x5000.CPU 1 writes word
40@ address0x5000
Figure 2 shows that accesses 1 and 2, which are reads, trigger compulsory cache misses in both CPU 1’s and CPU 2’s caches. The two caches must request the corresponding block from memory, via the communication bus. Each processor gets a copy of this block (and therefore a copy of the word @ address 0x5000) and stores the block on their own cache.
CPU 2 reads Mem[0x5000]
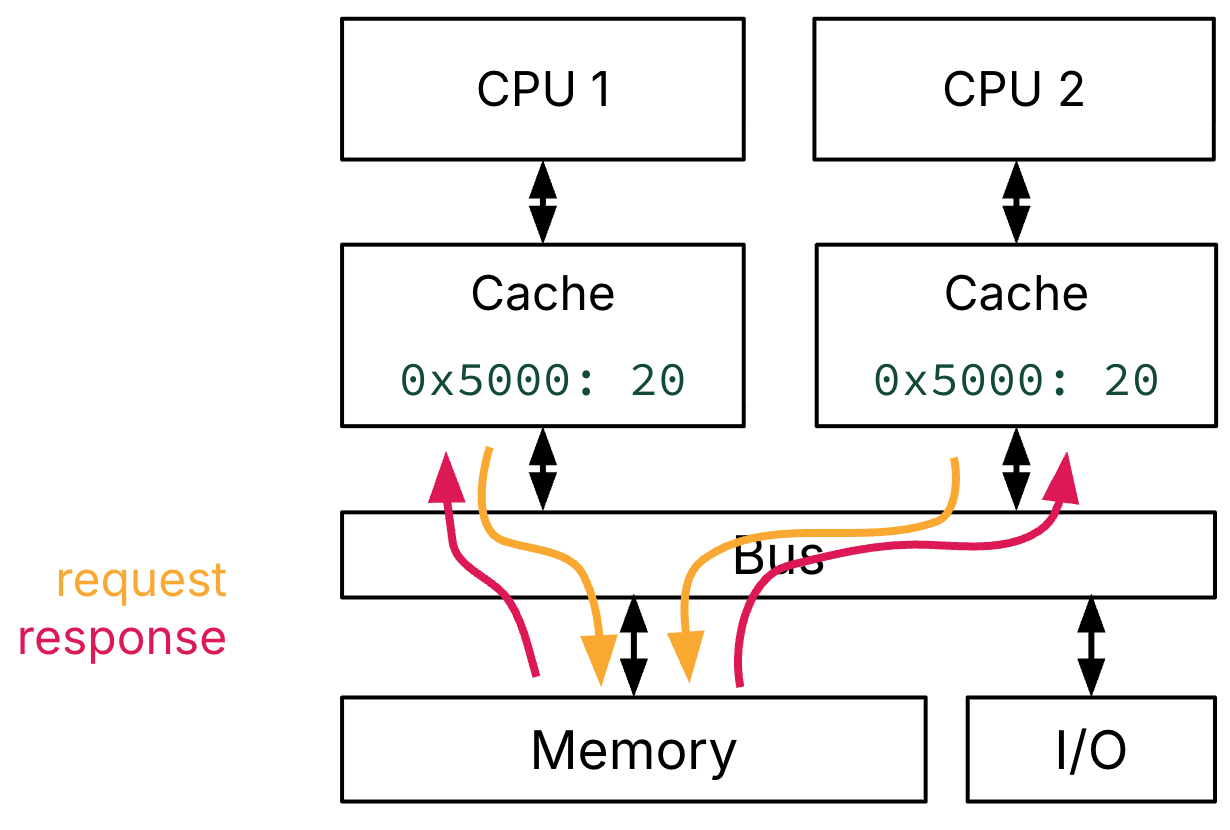
Figure 2:CPU 1 and CPU 2 both read a word @ address 0x5000. If both caches are cold, these two memory accesses are compulsory cache misses, and the value must be retrieved from shared memory via the shared bus.
The issue is revealed with Figure 3, which illustrates access 3, which is a write. When CPU 1 performed a write, CPU 1’s cache was up-to-date, but CPU 2’s cache is now stale, and it doesn’t know.
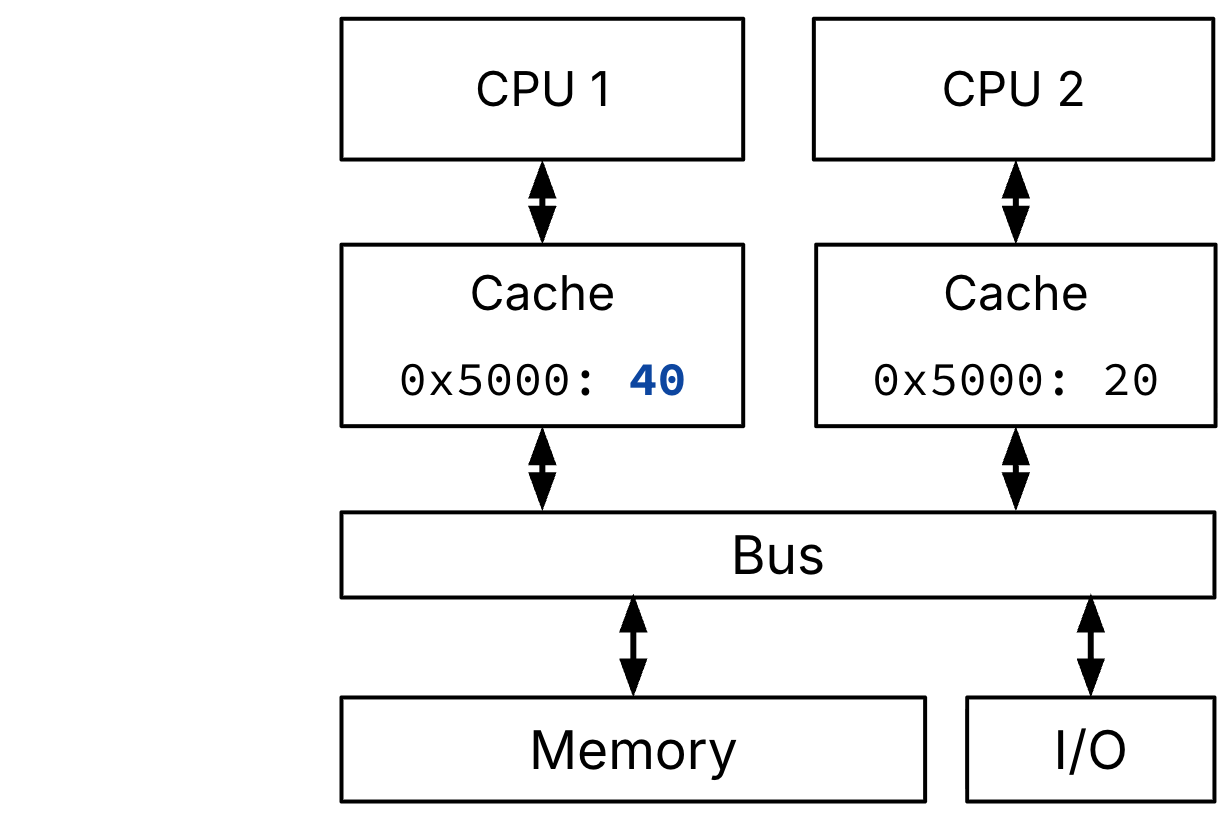
Figure 3:CPU 1 performs a memory write to word 40 @ address 0x5000. In a non-cache coherent system, CPU 1 and CPU 2 now have different copies of the same region of memory.
The last access in our example illustrates that this system is not cache coherent. From Wikipedia:
In a cache coherent system, if multiple clients have a cached copy of the same region of a shared memory resource, all copies are the same.
P&H defines cache coherence as the aspect that defines what values can be returned by a read. There must be a way of enforcing the “coherency” implied by the phrase: “all copies are the same.” We do so using an additional type of cache miss.
4Coherence Miss¶
To enforce cache coherence, we introduce a fourth type of cache miss: a coherence miss, e.g., a communication miss caused by writes to shared data made by other processors.
Such misses are commonly part of cache coherence protocols, which are means of maintaining coherence for multiple processors. For example, a protocol can ensure that a processor has “exclusive access” to a data item by invalidating copies in other caches on a write. Subsequently, a processor that reads (or writes) to an invalidated copy then misses in the cache; this miss is categorized as a coherence miss.
5Snooping Protocols¶
One version of the write invalidate cache coherence protocol described above is a snooping protocol. When any processor accesses memory, use the bus to “snoop”[2] and notify other processors.
Each cache controller “snoops” for write transactions on the common bus. On another processor’s block request to the bus, check if one’s own cache has a copy.
If a copy exists, and the request is a read, do nothing.
If a copy exists and the request is a write, then invalidate one’s own cache’s copy.
If a copy does not exist, do nothing.
This snooping protocol permits many processors to have copies of data that are only read, and permits a processor that is writing to have an exclusive copy of the data (because other copies are invalidated).
5.1Details¶
MOESI is a full cache coherence protocol that describes the states in other cache protocols: Modified Owned Exclusive Shared Invalid.
For each block in a cache, track state:
Shared: up-to-date data, other caches may have a copy
Modified: up-to-date data, changed (dirty), no other cache has a copy, OK to write, memory out-of-date (i.e., write back)
Invalid: not in cache (from before: valid flag)
Two enhancements:
Exclusive: up-to-date data, no other cache has a copy, OK to write, memory up-to-date. Avoids writing to memory if block replaced, and supplies data on read instead of going to memory.
Owner: up-to-date data, other caches may have a copy (they must be in Shared state). This cache is one of several with a valid copy of the cache line, but has the exclusive right to make changes to it. It must broadcast those changes to all other caches sharing the line. The introduction of owned state allows dirty sharing of data, i.e., a modified cache block can be moved around various caches without updating main memory. The cache line may be changed to the Modified state after invalidating all shared copies, or changed to the Shared state by writing the modifications back to main memory. Owned cache lines must respond to a snoop request with data.
UC Berkeley has explored various snooping[3] protocols; see an advanced computer architecture course for more information.
Given the shared address space, a more accurate term for shared memory multiprocessor might be shared-address multiprocessor. You may also see the term symmetric multiprocessor, but we digress.
From Merriam-Webster: to look or pry especially in a sneaking or meddlesome manner.