1Learning Outcomes¶
Compare and contrast the terminology of caches and virtual memory.
Trace the steps of memory hierarchy access when we assume physically indexed, physically tagged caches.
Use AMAT to motivate why designing systems for extremely low page fault rate is so performance-critical.
🎥 Lecture Video
We are finally, finally ready to consider access to the full memory hierarchy. How does this memory hierarchy improve performance?
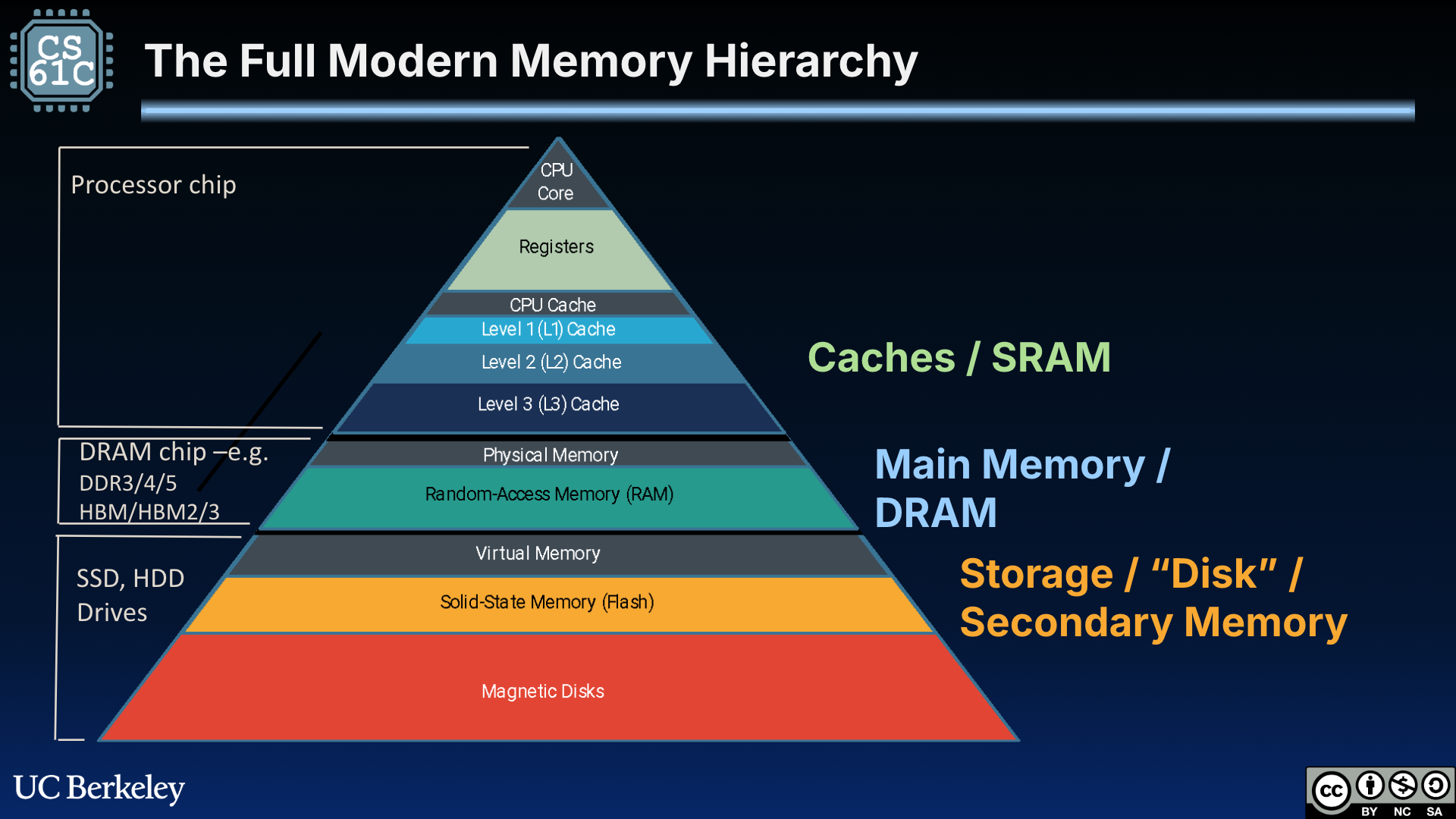
Figure 1:The full memory hierarchy. Now, we consider access to memory caches, main memory (primary storage), and disk (secondary storage).
2Virtual Memory and Caches¶
Virtual memory and caches are tricky to work with together because they do not use the same terminology, nor are they implemented similarly. Virtual memory was a historic concept created out of the limitations of tiny memory; the concept came before caches, which were built to make performance fast. Nevertheless, they are both layers in the memory hierarchy.
To compare virtual memory to caches, let us consider a horizontal view of the memory hierarchy shown in Figure 2.
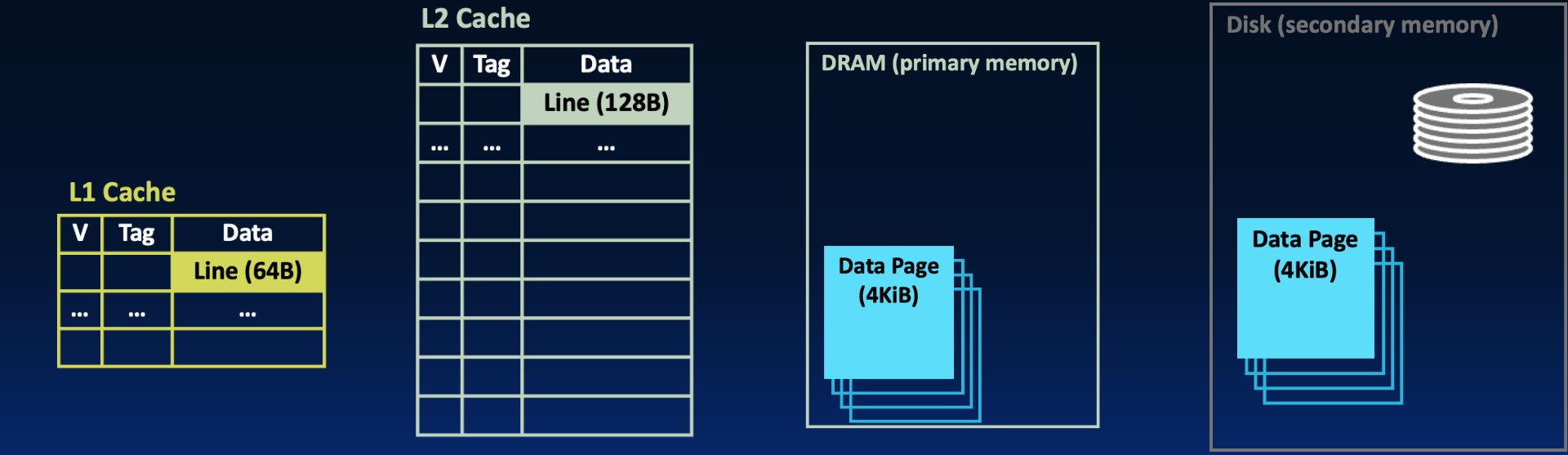
Figure 2:Layers of the hierarchy on the left are closer to the CPU and access is faster; as we move right, modules get further from the CPU and access is much slower.
Terminology: Memory units. Blocks, pages, words, bytes are all units in the memory hierarchy. In Figure 2 above:
Caches copy blocks (or lines) from main memory. On modern systems, blocks are 64B or 128B.
Memory is organized into pages. These pages are copied from disk. On modern systems, pages are 4-16 KiB.
Copies of data. Remember what we learned when we first explored other layers of the memory hierarchy in a previous section:
Caches are a quick-access copy of data in main memory.
Main memory is a “quick”-access copy of data on disk.
In Figure 3,
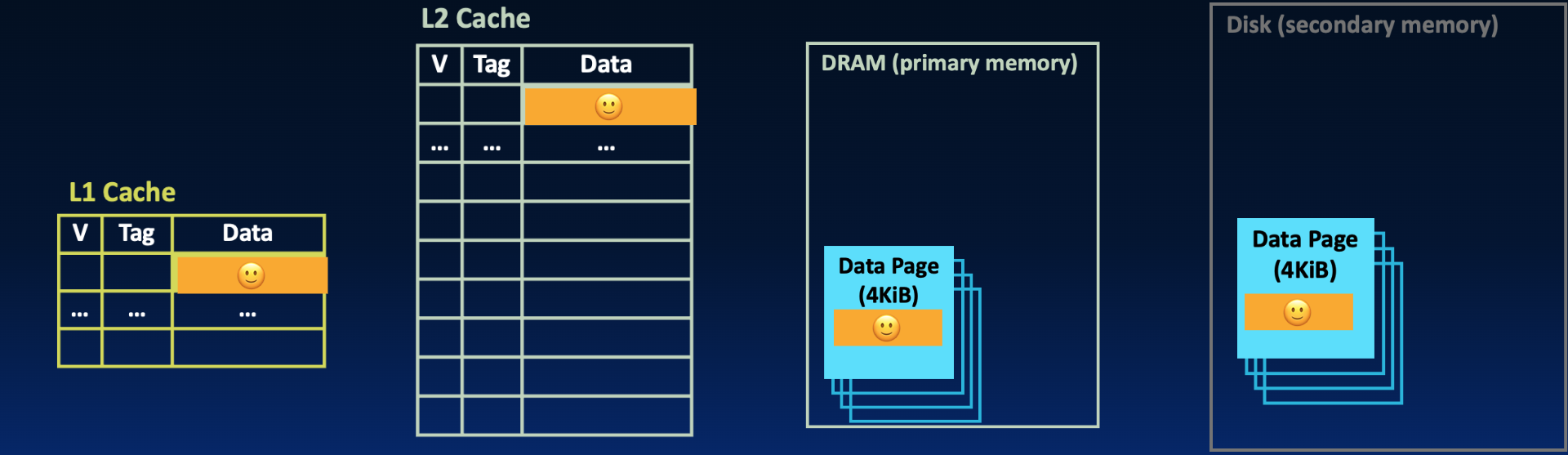
Figure 3:The 🙂 data in the L1 cache is also available in a block of the L2 cache, on a physical page of main memory, and on a disk page.
Recall from an earlier section, page tables do not have data; they help translate addresses and facilitate demand paging.
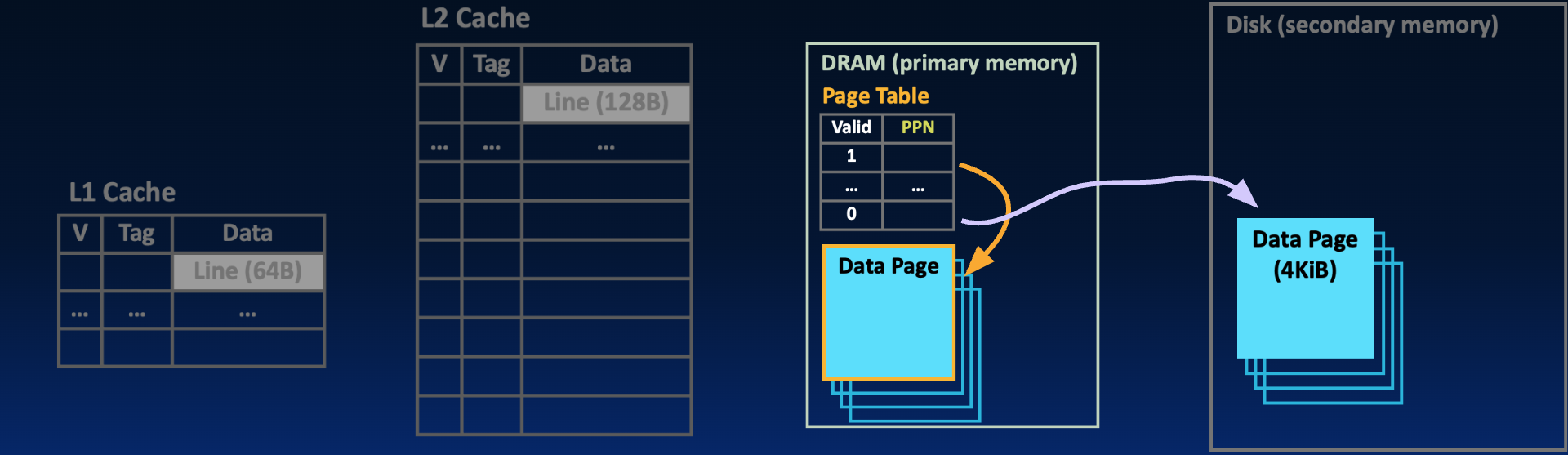
Figure 4:With demand paging, pages on disk are loaded into memory only when needed by the process. The location of each page is tracked by status bits the page table—here, the valid bit in each page table entry, combined with the physical page number (if the valid bit is set).
The full comparison of these two parts of the memory hierarchy is in Table 1.
Table 1:Terminology of virtual memory vs. caches.
| Feature | Caches | Virtual Memory |
|---|---|---|
| In memory hierarchy | Caches ↔ Memory | Memory ↔ Disk |
| Memory unit | Line or Block (~64 bytes) | Page (~4096 bytes) |
| Miss | Cache Miss | Page Fault |
| Associativity | Direct-mapped, N-way set associative, fully associative | “Fully associative” (location determined by OS) |
| Replacement policy | Least-recently-used (LRU) or random | LRU (most common), FIFO, or random |
| Write policy | Write-through or write-back | Write-back |
Table 1 above does not include terminology for the TLB, which is our cache for address translations. To differentiate misses in the TLB from those in memory caches, we use the terminology: TLB hit, TLB miss.
3Physically Indexed, Physically Tagged Caches¶
We would love to put everything together: memory caches, TLB, page tables, disks—you name it! But what order do we put things in? Consider the following questions as you look at Figure 5:
Can a cache hold the requested data if the corresponding page is not in main memory?
When should we translate virtual addresses?
On a memory reference, what should we access first?
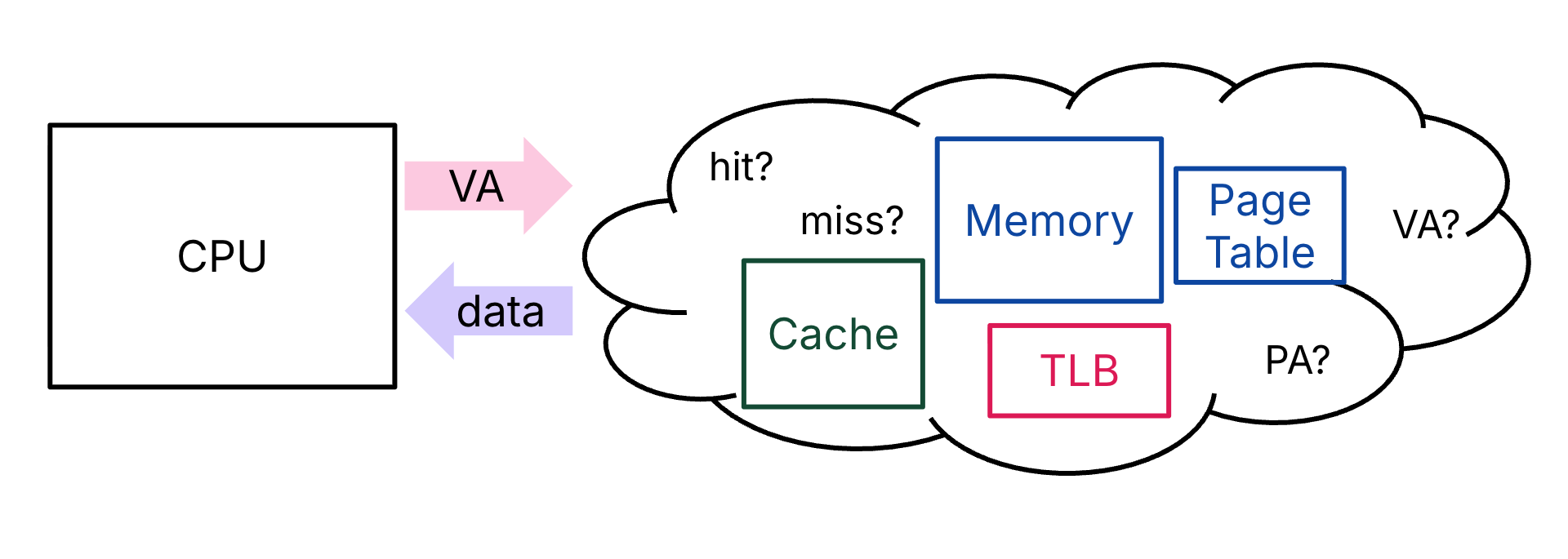
Figure 5:Putting it all together: what is the order in which we access things? This scenario assumes one layer of caches.
Other more complicated designs exist, but in this class we assume physically indexed, physically tagged (PIPT) caches. In Figure 6, the fully associative TLB uses the virtual page number to construct its tag, [1]. By contrast, the memory cache uses the physical address to construct its tag and index, and the cache is indexed via this physical index. Note that page offset and block offsets are different sizes, because blocks are smaller than pages.
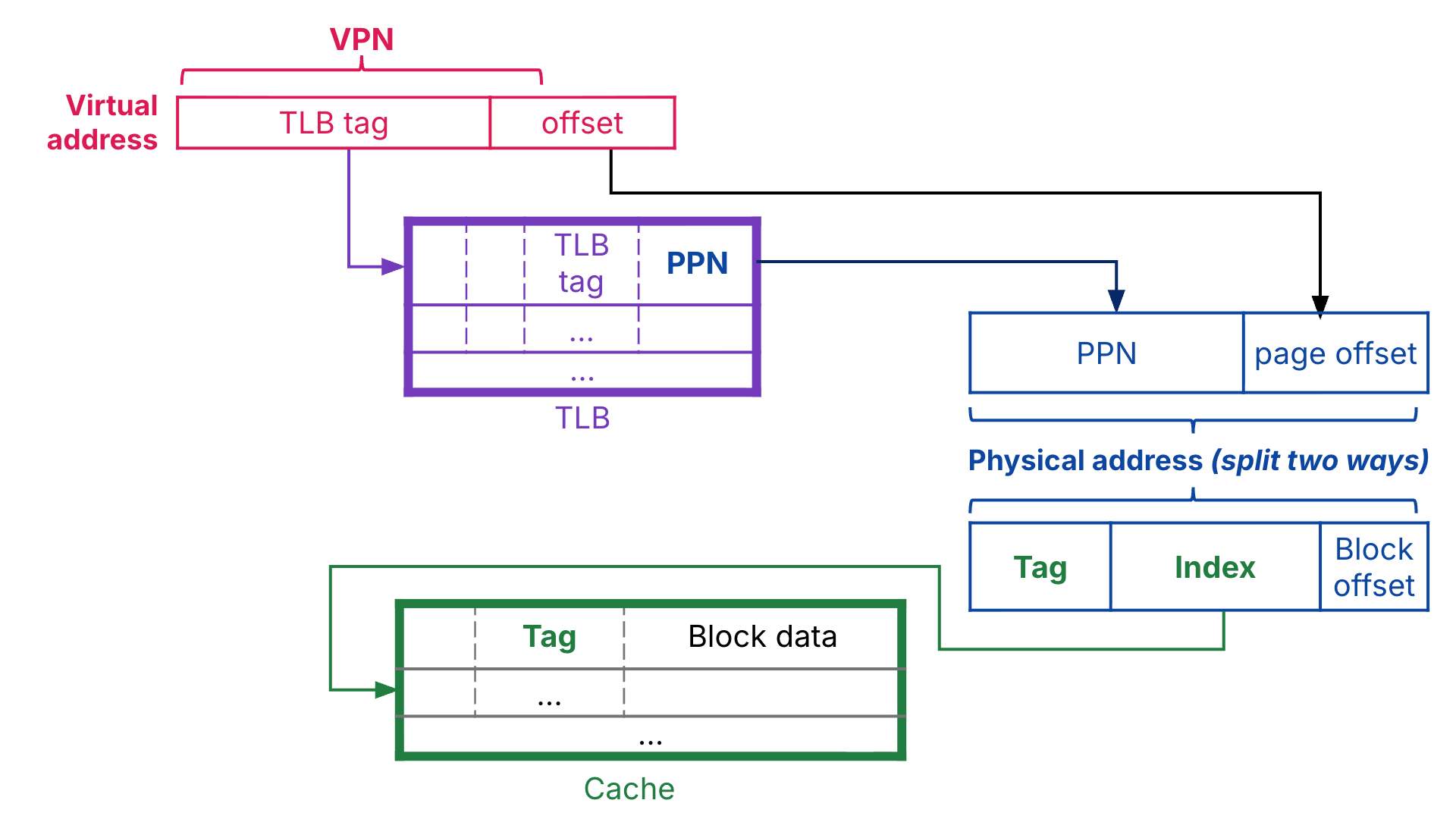
Figure 6:Physically indexed, physically tagged caches.
A PIPT cache design determines the order of access as shown in Figure 7:
Address translation: First translate virtual address to physical address.
Data access: Use the physical address to access the data in the memory hierarchy.
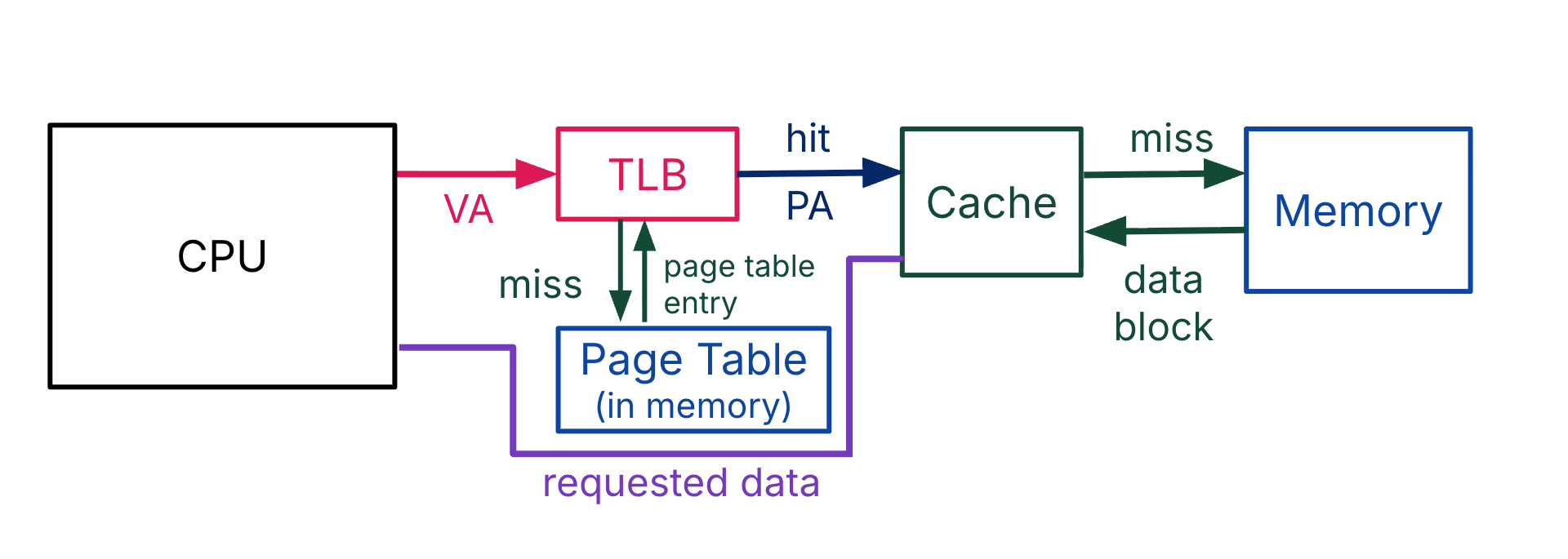
Figure 7:With PIPT caches, address translation happens first. This memory scenario assumes one layer of caches.
4Revisiting AMAT: Impact of Paging¶
At a high-level, see Table 2.
Table 2:Memory hierarchy metrics (review terminology): Hit rate, hit time, miss rate, and miss penalty. We ignore the TLB for simplicity in computing AMAT, but advanced readers can try incorporating it.
| Feature | Cache | Virtual Memory |
|---|---|---|
| Unit | Block (32-64 B) | Page (4-16 KiB) |
| Miss rate | 1% to 20% | 0.001% |
| Hit time | ≈ 1 cycle | ≈ 100 cycles |
| Miss penalty | ≈ 100 cycles | ≈ 5M cycles |
Let’s compute AMAT for a specific example. Suppose we have the following parameters (with no TLB):
L1 cache: Hit time 1 cycle, hit rate 95%
L2 cache: Hit time 10 cycles, hit rate 60% (of L1 misses)
DRAM: Hit time 200 cycles, with some hit rate
Disk: 20,000,000 clock cycles.
Note that for a 2 GHz clock, 200 cycles is 100 ns, and 20,000,000 cycles is 10 ms.
Suppose we only have DRAM and never access disk. Average memory access time in this case is below:
With paging, i.e., disk access, define a rate that is our “hit rate” to memory. Equivalently, is our probability of a page fault. AMAT becomes:
The second factor is a performance cost proportional to the performance of our demand paging system. We mentioned above in Table 2 that a miss rate for VM is 0.001%. This is our page fault rate, . = 0.001% = 0.00001 seems like a tiny rate, but we can see quickly how AMAT explodes with higher rates:
:
:
:
The last of these is about 680 times slower than the first of these. That’s really, really, REALLY slow...!
Given this analysis, we hope we have convinced you how costly page faults are, and why switching to software with the OS to determine page placement and replacement in memory is well worth it.
That wraps up virtual memory and our exploration of the memory hierarchy! Congratulations!!!
In low-associativity TLBs, the virtual page number is split into the TLB tag and the TLB index; then, the TLB is indexed by this “virtual index.”
Often, the physical index and tag comprise the physical page number.
If there are multiple levels of caches, treat them all as part of the “Cache” block in Figure 7 and assume they are all physically indexed, physically tagged. If there is a miss in a higher-level cache, go to a lower level of cache. If the lowest-level cache misses, then go to memory and get a block for the lowest-level cache, then copy the block to the second-lowest-level cache, etc.