1Learning Outcomes¶
Identify the two accesses to memory hierarchy systems in virtual memory systems: address translation and data access.
Describe the TLB and its use. List reasonable parameters for the TLB.
Define a page table walk.
Compare address translation performance with the TLB.
🎥 Lecture Video
🎥 Lecture Video
Consider the address translation discussed in an earlier section. If we have a 1-MiB page table and a 128-KiB L1 cache, the page table must be stored in memory, not in the cache.
2Page Table Walks¶
At present, we must perform a page table walk, meaning we must access the page table to get the physical page number for address translation.[1] Remember that the current process’s page table is located main memory. Because page tables are located in memory (Figure 1, then we must access main memory twice. This takes several hundred cycles!
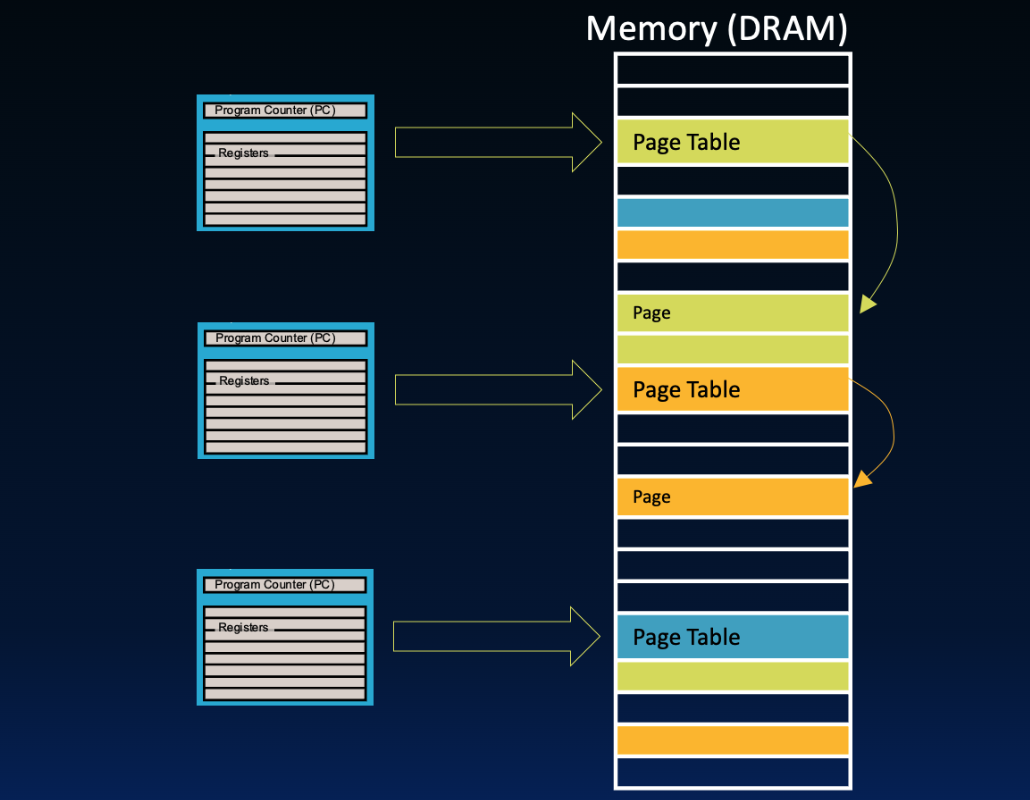
Figure 1:In address translation, there can be two access to memory on every load or store instruction.
To minimize performance penalty, we have two options for speed-up that leverage the cache:
Address translation: Use a cache for frequently or recently used page table entries.
Data access: Copy blocks from main memory to the cache.
To address the latter, see our unit on caches and our next section. To address the former, in this section we introduce the translation lookaside buffer.
3The Translation Lookaside Buffer¶
The translation lookaside buffer (TLB), or translation buffer, caches address translations, i.e., VPN-PPN mappings. It is usually separate hardware from memory caches and (like memory caches) is stored close to the CPU.
As shown in Figure 2, the TLB stores a subset of address translations for the current process’s page table. The TLB leverages locality and stores recently accessed translations.
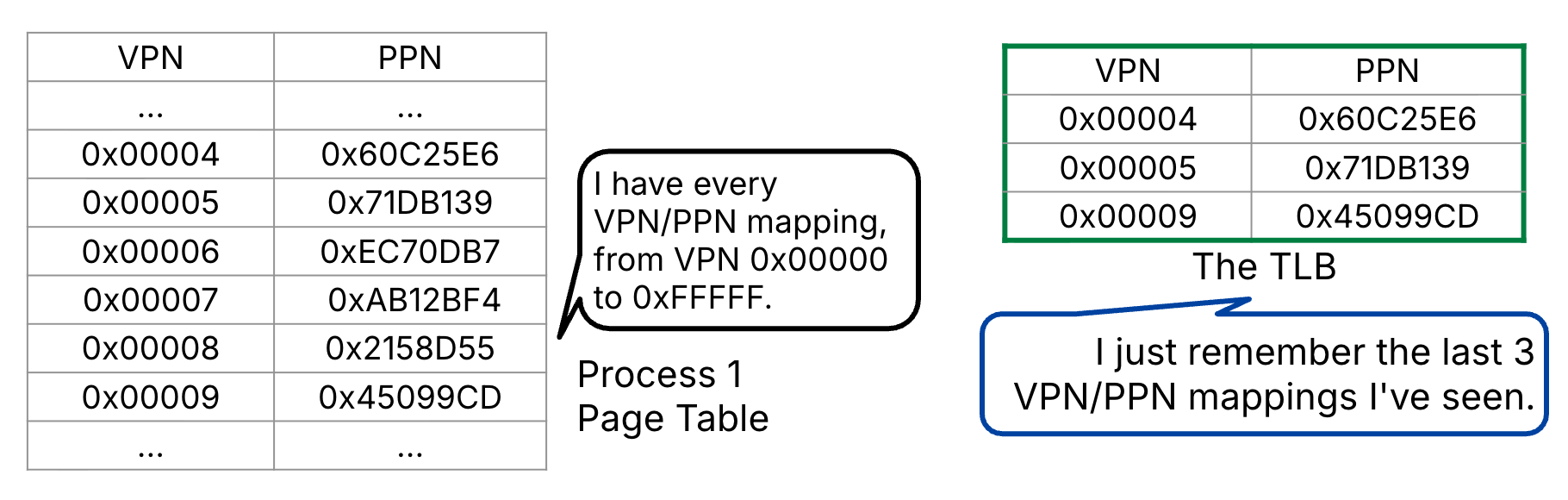
Figure 2:The Translation Lookaside Buffer (TLB) stores a subset of address translations.
Show Explanation
True. The TLB is (conceptually) a cache because it stores a subset of information located in a lower level of the memory hierarchy. Here, the information a TLB stores is a subset of VPN-PPN translations in the page table (unlike memory caches, which store a subset of data in main memory).
The TLB Reach is the number of virtual addresses can get immediately translated by the TLB. In other words, it is the size of the largest possible (disjoint) virtual address space that can be determined by the given entries in the TLB:
If the TLB “hits,” then no page table walk occurs, meaning we avoid accessing memory on address translation. Common TLB design:
38-128 entries
Fully associative, [2] which increases TLB reach by minimizing conflicting entries.
FIFO or random replacement policy
4Address Translation with the TLB¶
We have now introduced one type of “cache” into our virtual memory system: the TLB. This efficiency speeds up address translation, which is the first of the two accesses to the memory hierarchy.
Let us focus on the performance of the address translation by considering the toy scenario in Figure 3. Note that there is no memory cache, i.e., all data accesses must go to memory.
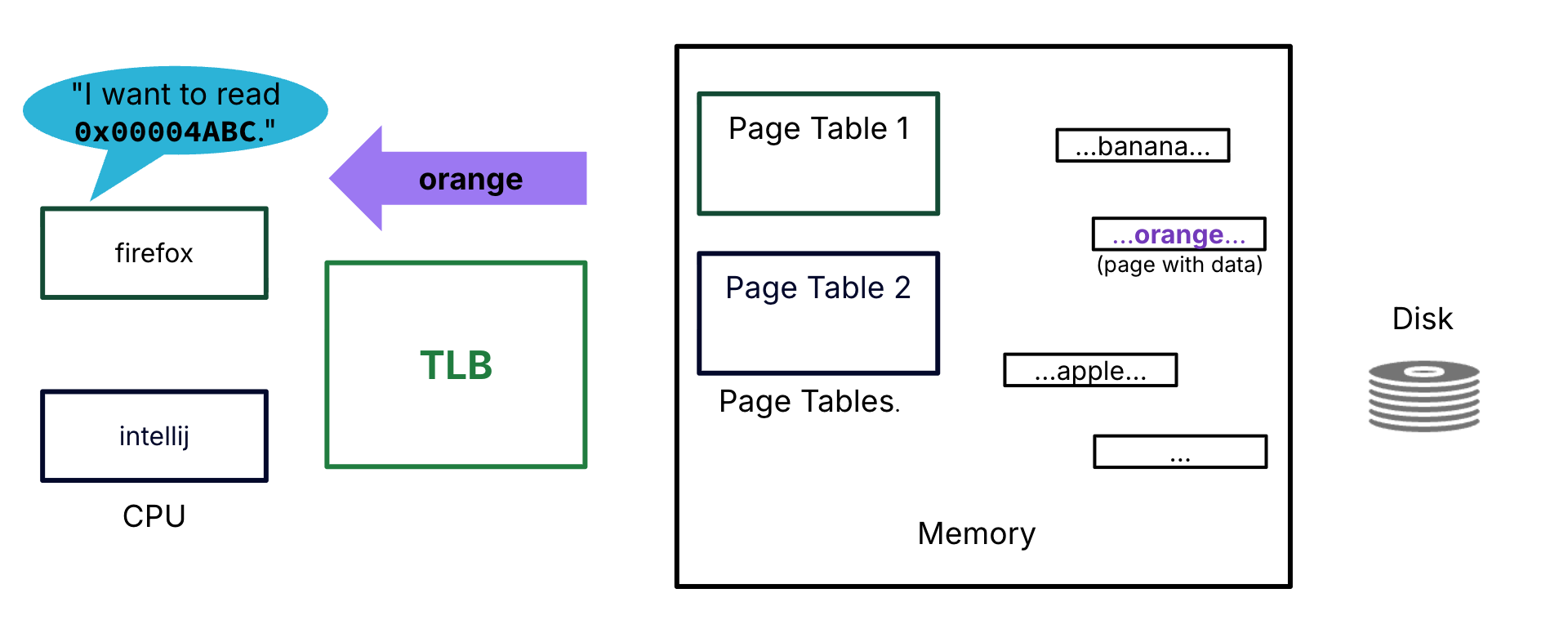
Figure 3:Memory hierarchy layout for this scenario. The page tables and a subset of pages for both processes (firefox and intellij) are stored in memory. Other pages are on disk. There is a TLB. There is no memory cache.
Firefox, the currently active process, requests data @ address 0x00004ABC:
The virtual page number (VPN) associated with this virtual address is
4.The physical page number (PPN) is
0x8C121D.The physical address of the data is
0x8C121DABCon the page with base address0x8C121D000.The data is orange (assume orange fits in, say, a memory word).
Let us compare three cases for translating the requested virtual address.[3] Toggle the tabs.
The requested VPN is in the TLB (e.g., it was recently accessed), so we retrieve the PPN from the TLB entry and translating the resulting physical address.
Address translation accesses just the TLB and is close to instant, on the order of a clock cycle.
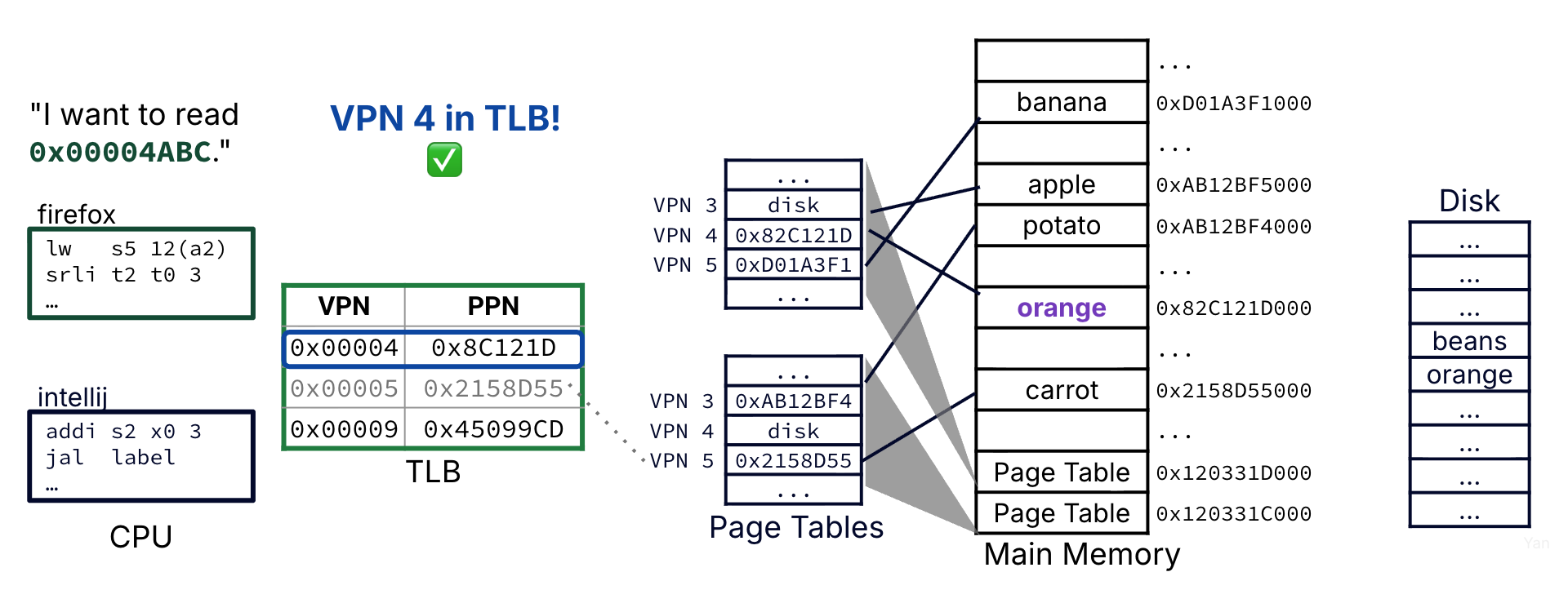
Figure 4:Case 1 is the best-case scenario: A TLB hit. Because the corresponding physical page is available in the TLB, no memory access is needed for address translation.
The requested VPN is not in the TLB, so we perform a page table walk to access the current process’s page table.
The page table entry for VPN 4 is accessed; it is valid, so we retrieve the PPN from the page table entry and translating the resulting physical address.
Before moving to the data access step, update the TLB. The page table entry for VPN 4 is inserted into the TLB (replacing an older entry) and marked with the current process PID.
Address translation accesses the TLB and memory and therefore takes on the order of a hundred clock cycles.
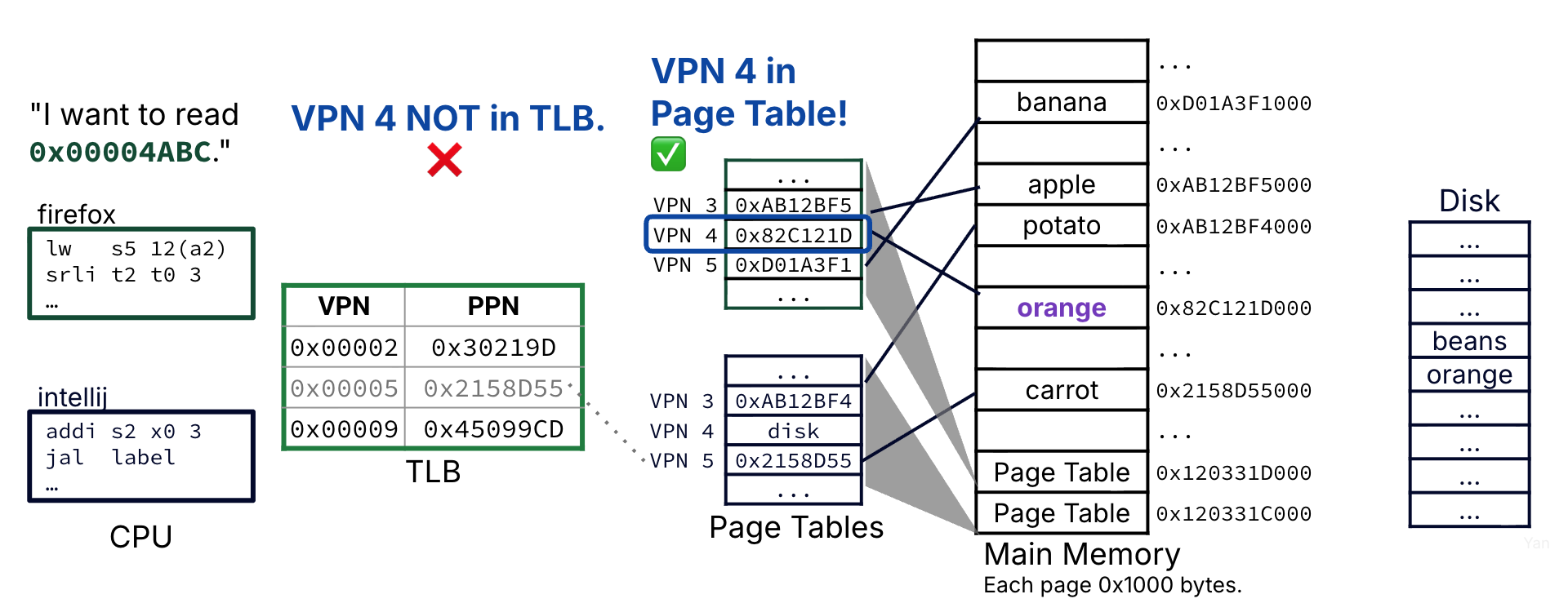
Figure 5:Case 2 is a slightly worse scenario: A TLB miss. However, because the physical page is in memory, the page table entry is valid. Access to main memory is needed for address translation.
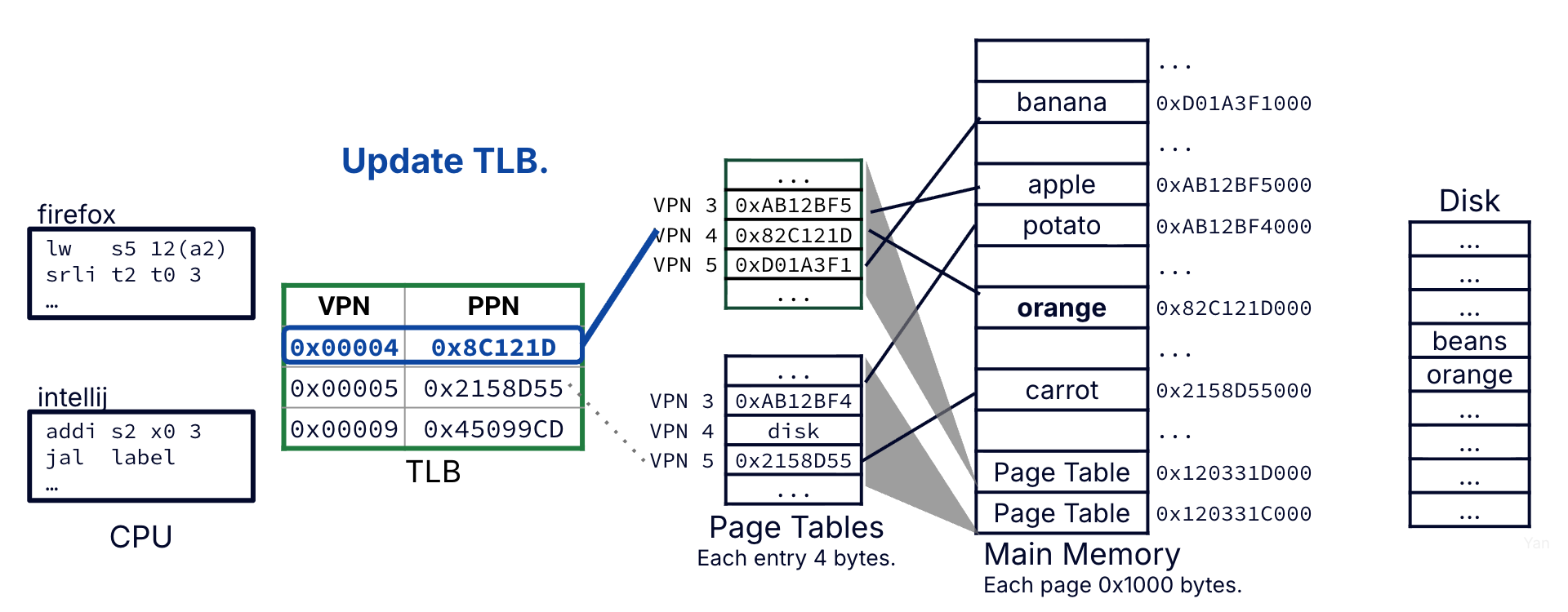
Figure 6:Case 2: Before moving to the data access step, update the TLB with the most recent translation (this one).
The requested VPN is not in the TLB, so we perform a page table walk to access the current process’s page table.
The page table entry for VPN 4 is accessed; it is not valid. Trigger a page fault exception.
The OS intervenes and requests the page from disk. It also performs a context switch to the another process while this process waits.
The page is loaded from disk into a physical page in memory. The page table entry for VPN 4 is updated with the PPN of the newly updated physical page, and mark the entry valid.
The page table entry for VPN 4 is accessed; it is valid, so we retrieve the PPN from the page table entry and translating the resulting physical address.
Before moving to the data access step, update the TLB. The page table entry for VPN 4 is inserted into the TLB (replacing an older entry) and marked with the current process PID.[4]
Address translation accesses the TLB, memory, and disk and therefore takes on the order of a thousand clock cycles.
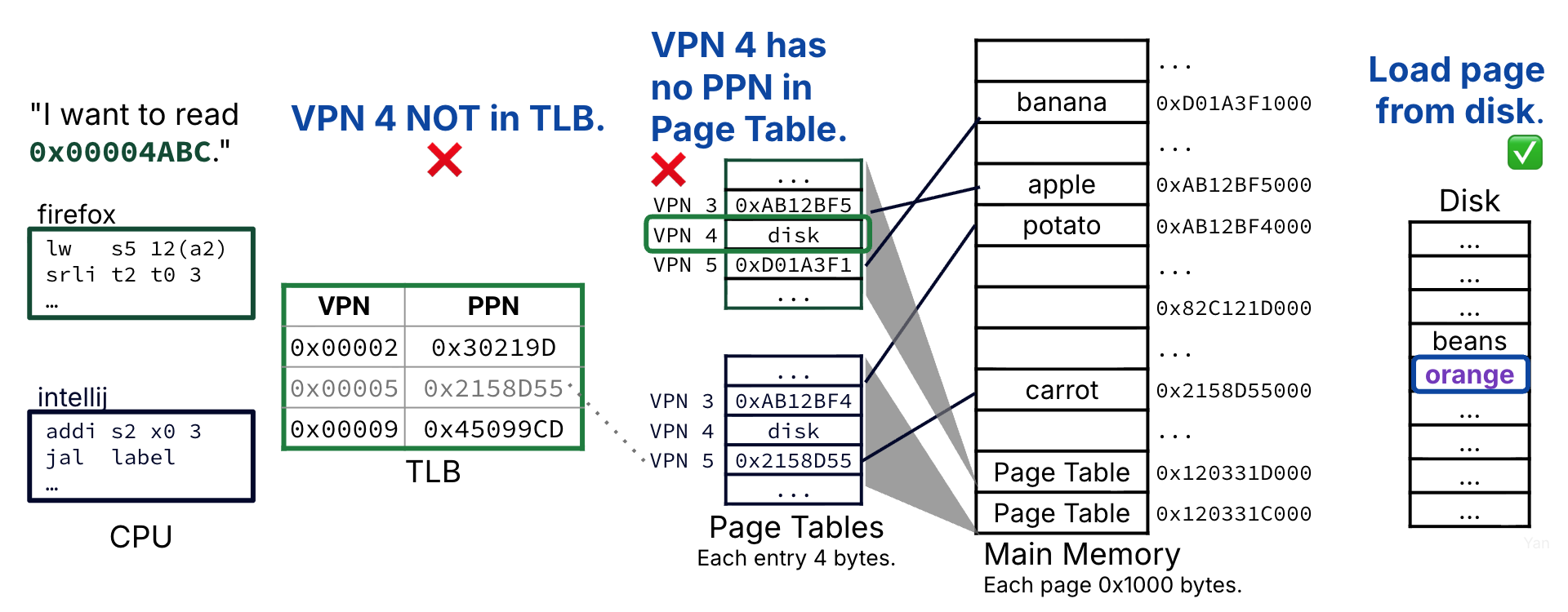
Figure 7:Case 3 is the worst-case scenario: A page fault. The physical page is not in memory, the page table walk does not yield a valid page table entry, and disk access is needed. Access to disk is needed for address translation. Access to main memory is needed for address translation.
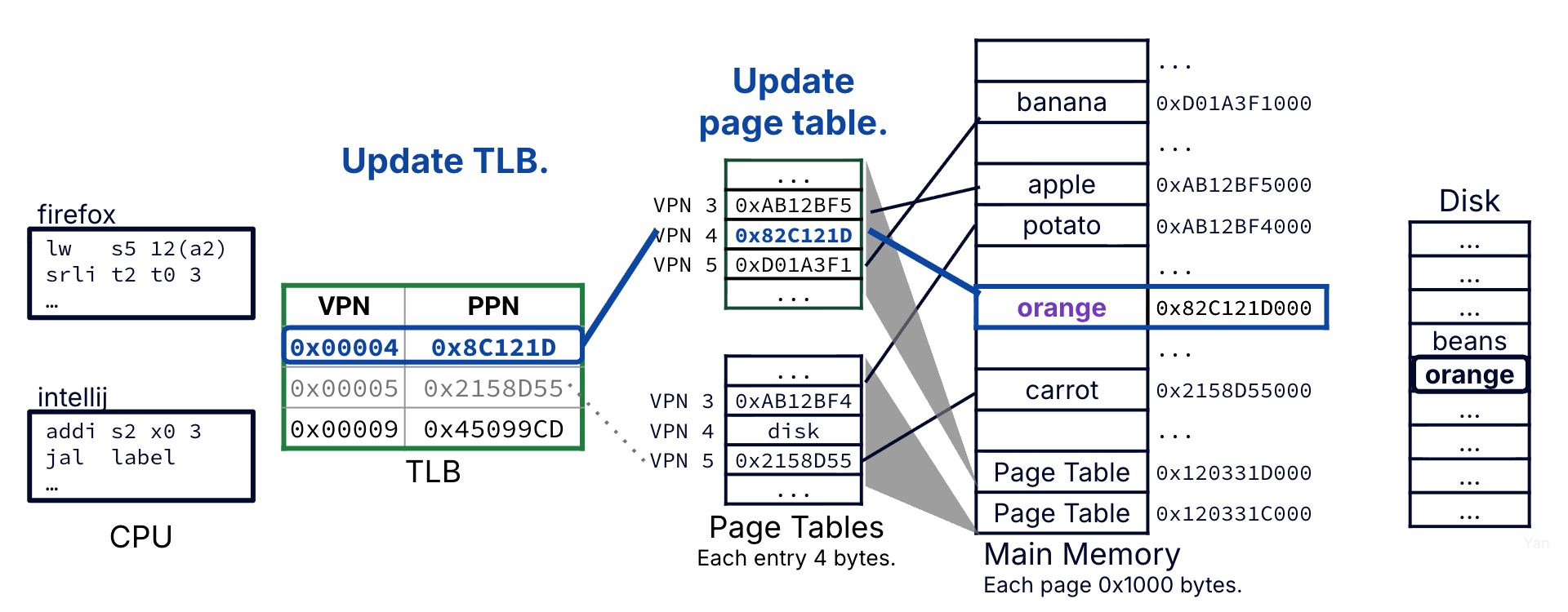
Figure 8:Case 3: When the disk is copied in from memory, the corresponding page table entry will be updated with the translation. Before moving to the data access step, update the TLB with the most recent translation (this one).
Table 1:Three address translation cases.
| Case | Performance | TLB | Page Table (in Memory) | Disk |
|---|---|---|---|---|
| 1 | Best (~1 cycle, TLB) | Hit ✅ | Not visited | Not visited |
| 2 | Worse (~100 cycles, memory) | Miss ❌ | Hit (Page Table Entry Valid) ✅ | Not visited |
| 3 | Worst (~1000 cycles, disk) | Miss ❌ | Miss (Page Fault) ❌ | Visited ✅ |
Show Answer
True. Remember: The TLB caches recent page table entries. If the entry is valid in the TLB, it must also be valid in the page table, and the data must therefore be in memory.
Finally, let’s put it all together by including memory caches to speed up data access. Let’s go!
The “walk” terminology makes more sense with hierarchical page tables, where multiple levels of page tables are accessed on each address translation. Hierarchical page tables are out of scope for this course.
In this course, we will assume that the TLB is fully associative. However, in practice, some TLB designs are set associative. In these cases, a Virtual Page Number is split into a TLB tag and a TLB index: the latter is used to determine the index of set; the former is used to determine a matching way within the set. This low-associativity TLB design can support other optimizations in address translation; see P&H Computer Architecture and later courses for details.
Imagine that during the context switch, the other process does not update any pages in the TLB. This is unlikely, but our toy scenario is contrived for simplicity.